‘Kun je dit databestand even opslaan in ons datawarehouse?’ – hoe vaak hoor je als data-analist of data engineer deze vraag tussen neus en lippen door even langskomen? Alsof data opslaan in een datawarehouse hetzelfde is als een bestandje opslaan in het juiste mapje op je computer. Data structureren in het datawarehouse verdient aandacht. Wat zijn de beste manieren van het opslaan? Tipje van de sluier: alles hangt af van en staat met de juiste structuur.
 Door Harmen, CTO & senior data scientist bij Datalab
Door Harmen, CTO & senior data scientist bij Datalab
Een datawarehouse is een verzamelplek voor (potentieel) alle data van je organisatie. Of het nu gaat om de administratie in Exact Online, ERP-data uit bijvoorbeeld Microsoft Dynamics of zelfgebouwde systemen, data ontsluiten is een cruciale eerste stap om waardevolle inzichten op te halen. Er zijn veel verschillende soorten datawarehouses en soorten technieken om data van de bronnen naar je datawarehouse (ETL: Extract/Transform/Load) te krijgen, zie ook de blog van Koen.
Een essentiële stap die niet -of te snel- genomen wordt, is nadenken over hoe je je data in het datwarehouse opslaat. Ofwel: welke structuur geef je aan de data in je datawarehouse?
‘Uitleggen waarom data ontsloten moet worden in een datawarehouse lukt wel, maar door tijdsdruk -‘mijn manager wil snel resultaten’- worden bronnen al snel ad-hoc ontsloten. Zonder goed na te denken over welke waarde je nog meer uit die data kunt halen.’
Structureren van data is van groot belang
Het structureren van data is zelfs zo essentieel dat grote organisaties veelal er een aparte rol voor in het leven roepen: die van data-architect. In deze rol ben je verantwoordelijk voor het ontwerpen én bewaken van de structuur van het datawarehouse naast eventuele andere opslaglocaties, zoals een data lake. Kleinere organisaties hebben vaak maar één of enkele analisten in dienst die, naast het ontwerpen van dashboards en de uitvoering van analyses óók verantwoordelijk zijn voor het ontsluiten van data al dan niet in een datawarehouse. De rol van architect schiet er daardoor vaak bij in. Het uitleggen waarom data ontsloten moet worden in een datawarehouse lukt nog wel, maar de wens van snel zichtbare resultaten opleveren zorgt er voor dat bronnen vaak ad-hoc worden ontsloten, zonder de tijd te nemen goed na te denken over welke waarde je nog meer uit de data kan halen. Een gemiste kans!
Kimball’s sterschema’s en snowflakes, Inmon’s normalisatie, of toch Linstedt’s Data Vaults?
Hoe en wat je in je datawarehouse opslaat hangt af van:
- wat je er mee wilt kunnen (specifieke analyses of flexibel inzetbaar);
- of er sprake is van retentie van data of vooral een kopie van productiesystemen;
- en de eigen voorkeuren voor wat betreft standaarden.
We behandelen nu de drie meestvoorkomende standaarden. Elke standaard heeft z’n eigen voors en tegens en deze blog is een goed startpunt maar zeker niet een finale behandeling van welke standaard de beste is.
Inmon’s datanormalisatie
Als iemand aan te wijzen is als de ‘godfather’ van datawarehousing, dan is het wel Bill Inmon. Eind jaren-80 bedacht hij de term datawarehousing én formeerde een set van standaarden. Deze standaarden waren jarenlang dominant en zijn nu, ruim 35 jaar na introductie, nog steeds relevant. In de kern is een datawarehouse volgens Inmon een plek waar data over een specifiek onderwerp (afdeling van een bedrijf zoals sales en/of productie) samenkomt:
- op een geïntegreerde manier (meerdere bronnen zijn koppelbaar);
- waarin data genormaliseerd opgeslagen wordt (verderop meer hierover);
- onveranderbaar is (in SQL-termen: je bent vooral INSERT-queries aan het draaien om data toe te voegen en blijft meestal weg van UPDATE-queries);
- …zodat je de historie over tijd kunt zien.
Datanormalisatie is hierbij het kernbegrip. In feite komt normalisatie er op neer dat je data nooit dubbel opslaat. Bekijk het plaatje hieronder van een (fictieve en over-versimpelde) webshop. Je ziet aan de linkerkant een voorbeeld van een niet-genormaliseerd datamodel. Veel analisten werken graag met dit soort data omdat het makkelijk te gebruiken is in een dashboard-tool of voor een regressie- of machine-learninganalyse. Je hebt maar één tabel en deze tabel bevalt alles wat je nodig hebt. Maar… wel geschikt gemaakt voor alleen die ene analyse. Het niveau van observatie is namelijk de klant. Voor een analyse over klanten (gemiddeld bestelbedrag, locatie, besteldatum) is de data erg geschikt. Voor een analyse over producten wordt het lastiger: de data is wel aanwezig (in de kolommen ‘product_1’, ‘product_2’ e.d.), maar een analyse welke producten het beste verkopen is best lastig. Immers: elk willekeurig product kan voorkomen in elke product-kolom. Niet handig. Veel beter is het om data los van elkaar op te slaan: producten, klanten en bestellingen krijgen elk een eigen tabel. Vanuit bestellingen trekken we lijntjes naar de producten en de klanten: een bestelling is niet gek veel meer dan een klant koppelen aan één of meerdere producten.
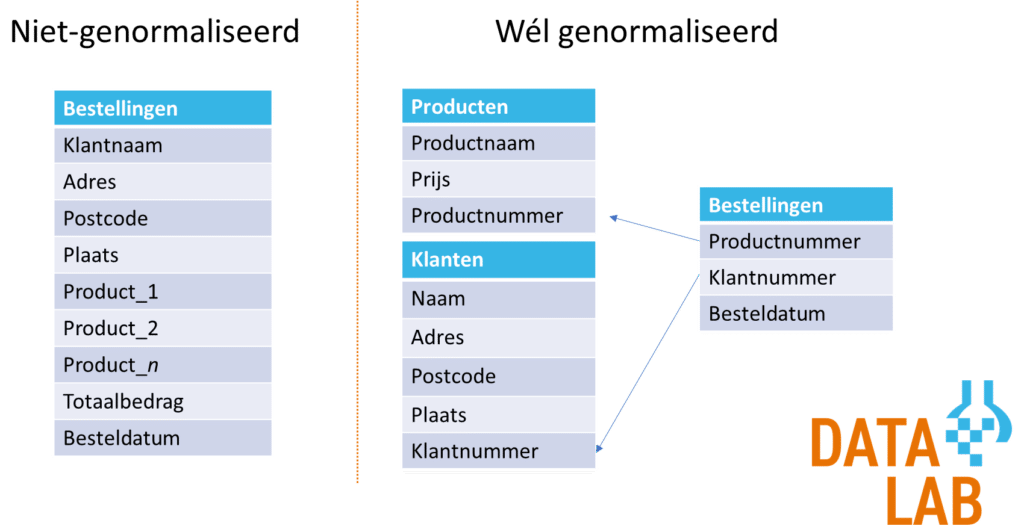
Het voorbeeld in de figuur is een overdreven simplificatie. In de werkelijkheid zijn er vaak nog veel meer tabellen waarin relevante informatie staat. Dit is ook precies de reden dat sommige analisten, ondanks de duidelijke voordelen van normalisatie, er toch voor kiezen om data niet-genormaliseerd op te slaan. Het is best wel een forse klus om de data goed te ontsluiten als het verspreid staat over veel verschillende tabellen.
De belangrijkste eigenschappen van het normalisatiemodel van (o.a.) Inmon:
- Data sla je maar één keer op. Voorbeeld: de naam van de klant sla je niet bij elke bestelling op. In plaats daarvan maak je een tabel met klanten aan en link je vanuit je bestellingen naar de klant.
- Alle tabellen verwijzen naar elkaar als er enige relatie tussen de tabellen is.
Kimball’s ster- en sneeuwvlokschema’s
Als een volledig genormaliseerd model te complex is, kiezen analisten soms ook voor de gouden tussenweg in de vorm van Ralph Kimball’s ster- of sneeuwvlokschema’s. Deze manier van data opslaan is een beperkte vorm van normalisatie van Bill Inmon. In plaats van alles aan alles koppelen, sla je één centrale feitentabel op. Rondom die feitentabel bouw je dimensietabellen. In de figuur hierboven bij het verhaal over Inmon is bestellingen de centrale feitentabel en zijn producten en klanten de dimensietabellen. Het cruciale verschil met Inmon’s model is dat je niet ook nog andere feitentabellen linkt aan de bestellingentabel. Informatie over bijvoorbeeld marketing (hoe heeft de klant de webshop eigenlijk gevonden?) wordt niet gekoppeld aan de bestellingen — althans, niet in dezelfde dataset. Je maakt voor elk feit (’bestelling’, ‘gevonden via’, etc.) een apart schema van tabellen.
Een sneeuwvlokschema is niets anders dan een nog verder uitgewerkte sterschema. In de tabel met klanten in de figuur hierboven zie je postcode en plaats staan. In Nederland hangen postcodes, adressen en plaatsen inherent samen. Je zou het model dus nog verder kunnen uitwerken door een postcode-huisnummer-dimensietabel te maken, waar je vanuit klanten naar linkt.
Linstedt’s Data Vaults
Zowel Inmon als Kimball schrijven voor wat een goede manier van data opslaan is. Dat is fijn en nuttig want het maakt samenwerken tussen analisten gemakkelijk, maar het kost ook veel tijd. Om die reden heeft Dan Linstedt een structuur van dataopslag uitgedacht die vooral geschikt is als je ruwe data op een slimme manier wilt opslaan, zonder nu al te kiezen voor één bepaalde manier van data opslaan. Het lijkt in die zin een beetje op een gestructureerd data lake of een data lakehouse.
Kernbegrippen zijn hubs, links en satellites. Hubs zijn je databronnen (bijvoorbeeld klanten in je ERP- en webshopsysteem), links zijn de sleutels waarmee je (bijvoorbeeld) de klanten in het ene systeem koppelt aan die in het andere systeem. In de satellites sla je de karakteristieken van de klanten op (naam, adres en wat je nog meer over je klant wil opslaan).
Welk datamodel kies ik?
Als simpele richtlijnen raad ik het volgende aan:
- Weet je zeker dat je data uitsluitend voor één analyse wil gebruiken? Sla de data dan niet-genormaliseerd op;
- Heb je enige tijd en ruimte om data grondig te ontsluiten, kies dan voor Inmon’s normalisatiemodel (zie ook de tip over views verderop);
- Wil je een trade-off tussen de tijdsinvestering en de flexibiliteit, overweeg dan Kimball’s sterschema;
- Heb je data, wil je dit opslaan maar weet je nog niet goed wat je er uiteindelijk mee gaat doen én heb je de tijd niet om het genormaliseerd op te slaan, overweeg dan het data Vault-model.
Veruit het meest populair is Inmon’s model met Kimball’s sterschema als goede tweede. Data Vaults worden weinig gebruikt, omdat nieuwe ontwikkelingen (data lakes) dit concept ingehaald heeft.
De 5 tips voor het ontsluiten van data
‘Genormaliseerde data + views = ultieme flexibiliteit.’
- Kijk goed naar de bron van je data. Heb je data uit een relationele database die je wilt ontsluiten? Probeer dan zo dicht mogelijk bij die structuur te blijven. Er is tenslotte al goed over nagedacht door de ontwerper van de applicatie. Focus liever op het maken van goede views op je data.
- Heb je data uit een API, dan heb je vaak maar één bepaalde blik op de data. Sommige API’s volgen netjes de onderliggende relationele databases, terwijl andere API’s sterk gericht zijn op het ontsluiten van data voor specifieke doeleinden (bijvoorbeeld voor het maken van een app in plaats van een kopie van alle data). Maak een overzicht van wat je allemaal met de data uit je bron kunt doen. Focus op de ‘quick wins’, het laaghangende fruit waarmee je je collega’s enthousiast kunt maken. Een dashboard dat wél dat handige overzicht biedt, wat de applicatie zelf niet kan. Of een analyse die direct leidt tot kostenbesparing of beter bediende klanten. Vergeet echter de middellange termijn niet: welke projecten wil je nog meer doen? En op lange termijn: welk nut zie je voor de bron op de langere termijn? De toekomst laat zich lastig voorspellen. Focus daarom voor een doordachte strategie voor in elk geval de korte en middellange termijn.
- Als je niet de data uit je bron 1:1 kunt ontsluiten in je datawarehouse (bijvoorbeeld omdat het teveel tijd kost om alle ETL-scripts te schrijven), zorg er dan in elk geval voor dat je de ruwe data uit je bron (bijvoorbeeld de JSON-data van een API of de ruwe database-dumps) in een data lake opslaat. Opslag daarin is vrij goedkoop, zeker als je goed uitzoekt hoe je data als archief opslaat in plaats van op hot storage. Zo kun je altijd terug in de data gaan. Wat je nu niet opslaat, kan zomaar onbeschikbaar zijn in een toekomstige versie van de bronapplicatie – of erger nog, verwijderd zijn.
- Kies voor een genormaliseerde data-structuur. Datalab werkt het liefst volgens de Inmon-standaard, omdat dit de grootste flexibiliteit geeft. Het kost net iets meer tijd dan de Data Vault-standaard, maar voor de (middel-)lange termijn is het vrijwel altijd een waardevolle investering. Bovendien leer je zo alle aspecten van je databron goed kennen en kun je ander ‘laaghangend fruit’ snel identificeren.
- Het grootste voordeel van een Kimball- of Data Vault-architectuur is dat je de data opslaat op een manier die sterk lijkt op de manier waarop de analist ermee aan de slag wil. In een genormaliseerd model van webshop-data heb je veel verschillende tabellen (producten, orders, verzendkosten, klanten, etc.). Een analist wil juist één of enkele tabellen met daarin alle informatie handig gekoppeld. Het is heel makkelijk om dat soort afgeleide datasets te maken op basis van de genormaliseerde brondata. Bij Datalab maken we voor klanten altijd views aan op de data. Dit zijn in feite queries op de data die je opslaat alsof het een tabel is. Je schrijft dus een query om te ontsluiten: klanten gekoppeld aan bestellingen en de bijbehorende producten, alles in één overzicht. Door deze query als view op te slaan, kan een analist (jij of je collega die de bron wellicht minder goed kent) alsnog eenvoudig werken met de onderliggende data. Ofwel: Genormaliseerde data + views = ultieme flexibiliteit.